Building a Real-World Security Benchmark for AI Code Scanners

Introduction
How do you know if your AI security scanner actually works?
Not on toy apps. Not on intentionally vulnerable code where every bug is planted like an Easter egg. I mean: can it find real, high-impact vulnerabilities in a real production codebase?
The kind that actually get CVEs. The kind that show up in security advisories. The kind that make you go "oh shit" when you read the description.
I couldn't find a good answer to that question. So I built a benchmark. Here's what it is, how it works, and why I think the AppSec community needs it.
The Problem with How We Evaluate Security Scanners
There are benchmarks out there. Quite a few, actually:
- OWASP Benchmark — a Java test suite with synthetic servlets, each containing (or not containing) a specific vulnerability. It's the closest thing to a standardized SAST evaluation, complete with scorecard generators.
- Juliet Test Suite — over 80,000 test cases from NIST/NSA covering 100+ CWEs. Each has a "good" and "bad" variant.
- OWASP WebGoat and Juice Shop — deliberately insecure apps designed for teaching, not benchmarking (though people use them for both).
- CWE-Bench-Java — a newer effort (2024) that uses 120 real CVEs from real Java projects like Apache ActiveMQ and Keycloak. Created for the IRIS paper on LLM-assisted static analysis.
CWE-Bench-Java is the most interesting of the bunch — it actually uses real-world code with real vulnerabilities. But it covers only 4 CWE types and only Java.
Here's my issue with most of these: they test whether your tool can spot a SQL injection in a self-contained servlet. The Juliet test cases are so regular that simple pattern-matching can score well without genuine program analysis. OWASP Benchmark's test cases are single servlets with straightforward data flows. Security practitioners widely report that tools scoring 90%+ on these benchmarks can miss 50%+ of vulnerabilities in their actual codebases.
And none of them test what matters to me right now: can a scanner find a sandbox escape in an agentic AI system's plugin loader, or a command injection hiding in a safe-bin policy refactor, or a broken authorization check in a multi-agent orchestration layer?
The agentic AI era introduced entirely new classes of security concerns — and the benchmarks haven't caught up.
Why OpenClaw?
OpenClaw is a personal AI agent framework. It's the kind of codebase that represents the new era of software:
- Agentic AI patterns — multi-agent orchestration, sandboxed execution, plugin systems
- Complex security surfaces — exec sandboxing, approval workflows, ACP runtime boundaries
- Active development — real PRs, real commits, real security advisories
- Non-trivial codebase — TypeScript, thousands of files, sophisticated architecture
The security advisories published against OpenClaw are real vulnerabilities that were found, triaged, and patched. They range from sandbox escapes to command injection to broken authorization — the kind of stuff that keeps security engineers up at night.
The reasoning is simple: if a scanner can find all the critical and high-severity vulnerabilities in OpenClaw, that's a meaningful signal. Not a synthetic benchmark score. A real-world capability proof.
How the Benchmark Works
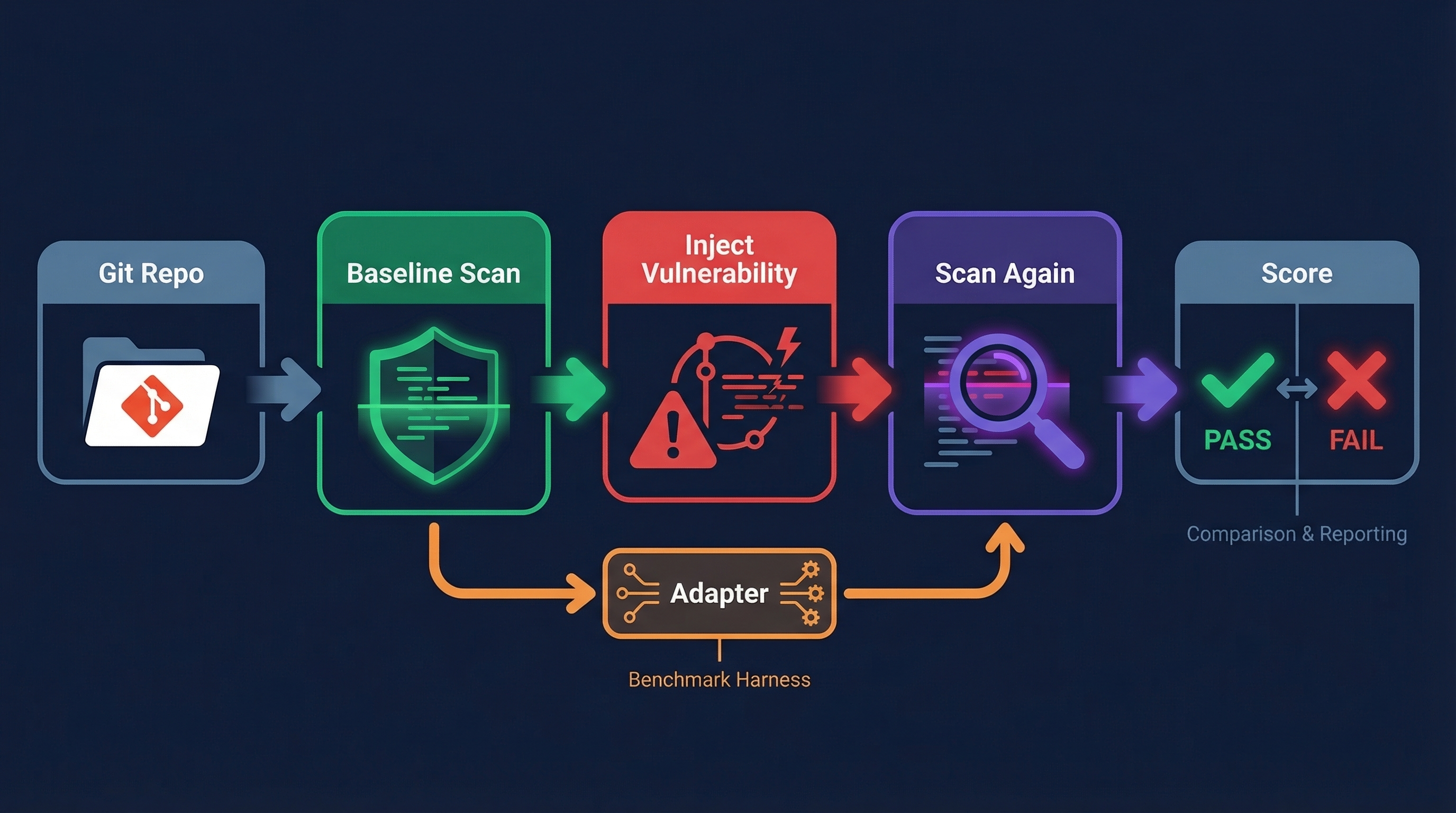
The openclaw-advisory-benchmark is straightforward in concept:
- Pick a real security advisory — each case maps to an actual GHSA (GitHub Security Advisory) published against OpenClaw
- Checkout the baseline — the clean commit before the vulnerability was introduced
- Run a baseline setup (optional) — let the scanner establish its understanding of the codebase
- Checkout the vulnerable code — switch to the commit that introduced the vulnerability
- Scan — ask the scanner to analyze the code and report findings
- Score — did it detect the vulnerability? Did it identify the right file and the right class of issue?
What's In the Benchmark
The benchmark currently has 24 cases spanning:
| Class | Count | Description |
|---|---|---|
brokenauthz | 6 | Broken authorization / privilege escalation |
commandinjection | 5 | Command injection / argument injection |
sandboxescape | 3 | Sandbox escape / isolation bypass |
authbypass | 3 | Authentication bypass |
codeexec | 2 | Arbitrary code execution |
secretdisclosure | 2 | Secret / credential disclosure |
pathtraversal | 1 | Path traversal / directory traversal |
ssrf | 1 | Server-side request forgery |
abuse | 1 | Resource exhaustion / denial of service |
Each case has structured metadata:
{ "schemaVersion": "1.0.0", "id": "GHSA-474h-prjg-mmw3", "advisoryUrl": "https://github.com/openclaw/openclaw/security/advisories/GHSA-474h-prjg-mmw3", "repository": "openclaw/openclaw", "advisory": { "title": "Sandboxed sessions_spawn bypassed sandbox inheritance...", "severity": "high", "cweIds": ["CWE-269"], "cvss": { "score": 8.1 } }, "timeline": { "baselineCommit": "a9d9a968...", "introducingCommits": [ { "sha": "a7d56e35...", "subject": "feat: ACP thread-bound agents" } ], "vulnerableHead": "a7d56e3554d088d437477d97d2c967754b9b1f5d" }, "expectedOutcome": { "vulnerabilityClass": "sandboxescape", "minimumSeverity": "high", "expectedPaths": ["src/agents/subagent-spawn.ts"], "description": "Scanner should detect sandboxescape when scanning vulnerableHead." }, "verification": { "status": "pass", "confidence": "high", "checks": [...] } }
Detection requires matching on path (did you find something in the right file?) and class (did you call it the right type of issue?). Severity is tracked but does not gate detection — a scanner that finds the right vulnerability at a lower severity still gets credit. For SARIF or simple JSON inputs, class is derived from the finding's CWE metadata.
Why this matters: a scanner that correctly identifies a sandbox escape but rates it "medium" instead of "high" has still demonstrated genuine understanding of the vulnerability. Severity calibration is a separate (and arguably less important) problem than detection itself. The scorecard tracks severity alignment so you can see how well your tool calibrates, but missing on severity alone doesn't count as a miss.
The Adapter Pattern
Every security scanner has its own interface. Different CLI flags, different output formats, different ways of thinking about "baseline" vs "incremental" scans.
The benchmark doesn't care about any of that. It needs exactly two commands:
baseline-cmd— "scan this clean code and remember it"scanner-cmd— "now scan this vulnerable code and tell me what's new"
The scanner output can be either SARIF 2.1.0 or a simple JSON format — both are auto-detected by the runner.
To bridge your scanner to the benchmark, you write an adapter — a thin script that translates between your scanner's interface and the benchmark's expectations. The benchmark README documents the expected output interface.
What Makes These Cases Hard
These aren't your typical benchmark cases. Here's what makes them genuinely challenging:
Contextual Reasoning Required
A sandbox escape in an agentic AI system isn't just "user input reaches eval()." It's about understanding that a plugin loader crosses a trust boundary, that workspace paths can be manipulated to escape a sandbox root, and that the combination of seemingly safe operations creates an unsafe state.
Intent Matters
One case involves a command injection hiding in a safe-bin policy refactor. The vulnerability? A dangerous flag (--compress-program) was dropped from a blocklist during a rename. Finding this requires understanding the intent of the policy — what it's trying to prevent — not just its syntax.
Multi-File, Multi-Commit Context
Many cases have introducing commits that span multiple files. The introducingCommits field in each case is an array — some vulnerabilities were introduced across multiple commits, not a single atomic change. The benchmark handles this by checking out the vulnerableHead (the final vulnerable state) rather than replaying individual commits. A scanner needs to understand how changes in device-pairing.ts interact with changes in server-methods/devices.ts to spot a scope escalation vulnerability. Single-file analysis won't cut it.
Agentic-Era Vulnerability Classes
Several cases involve vulnerability patterns specific to agentic AI systems:
- ACP (Agent Communication Protocol) tool invocation authorization
- Multi-agent orchestration boundary violations
- Channel-specific entrypoint authorization gaps
- Agent sandbox escape through workspace manipulation
Traditional SAST rules simply don't cover these. A scanner needs genuine reasoning capability.
How to Run It
The benchmark is open source. Here's what you need:
Prerequisites
- Clone the benchmark repo and the OpenClaw repo
- Write an adapter for your scanner (see the interface spec below)
- Python 3.9+
Running
python3 scripts/run.py \ --openclaw-repo /path/to/openclaw \ --scanner-cmd "your-scanner scan --json ." \ --format simple
For diff-aware scanners that need a baseline warmup:
python3 scripts/run.py \ --openclaw-repo /path/to/openclaw \ --scanner-cmd "your-scanner scan --json ." \ --baseline-cmd "your-scanner index ." \ --baseline-timeout 600 \ --format simple
You can filter to specific cases:
python3 scripts/run.py \ --filter GHSA-474h-prjg-mmw3 \ ...
Or set timeouts for long-running scanners:
python3 scripts/run.py \ --timeout 1200 \ --baseline-timeout 600 \ ...
Scanner Output Formats
The runner accepts two output formats (auto-detected by default):
SARIF 2.1.0 (recommended) — Industry standard. Severity is derived from security-severity rule properties when available, otherwise from the result level. CWE IDs are extracted from result properties or rule tags.
Simple JSON — Minimal format for scanners without SARIF support:
{ "findings": [ { "path": "src/gateway/server-methods/devices.ts", "severity": "critical", "ruleId": "command-injection", "message": "Command injection via user input", "cweIds": ["CWE-78"] } ] }
The benchmark scorer matches findings against expected outcomes:
- Path match — does any finding target one of the expected files?
- Class match —
expectedOutcome.vulnerabilityClassis matched from the finding's CWE metadata
Both must pass for a case to be scored as DETECTED. Severity is tracked in the scorecard but does not gate detection. Findings without CWE/class metadata cannot satisfy the class-match requirement.
A note on false positives: The current benchmark measures detection recall — did the scanner find the known vulnerability? It does not yet penalize false positives. A scanner that flags everything as critical would score 24/24 on detection but would be unusable in practice. Measuring precision (signal-to-noise ratio) is a planned addition — likely by tracking total findings per case and flagging scanners that produce excessive noise alongside their detections. For now, treat the detection score as a necessary-but-not-sufficient indicator of scanner quality.
What I Hope This Enables
Honest Comparison
Right now, every AI security tool claims to be revolutionary. Marketing decks show 95% detection rates on synthetic benchmarks. But nobody publishes results against real vulnerabilities in real code.
This benchmark is an invitation to change that. Run your scanner. Publish your results. Let's have an honest conversation about what these tools can and can't do.
Faster Iteration for Scanner Developers
If you're building a security scanner — whether it's LLM-powered, traditional SAST, or some hybrid — you need a feedback loop. "Did my change improve detection?" is a question you should be able to answer in minutes, not days.
With 24 cases and a simple pass/fail scoring model, you can run the full suite after every change and see exactly what improved and what regressed.
Community-Driven Expansion
The benchmark is designed to grow. Each case is a self-contained JSON file with advisory metadata, git timeline info, and expected outcomes. Contributing a new case means:
- Finding a security advisory with clear introducing commits
- Filling out the case template
- Running the verification script to confirm the git timeline is valid
- Submitting a PR
The more real-world advisories we cover — across different codebases, languages, and vulnerability classes — the more useful this becomes for everyone.
What's Next
This is v1. Here's what I'm working on:
- More cases — targeting 50+ cases across multiple codebases (not just OpenClaw)
- Multiple language support — the framework is language-agnostic, but we need Go, Python, and Rust advisory cases
- Automated case generation — tooling to semi-automatically create benchmark cases from published GHSAs
- Community leaderboard — a place to publish and compare results (if there's interest)
Try It
The benchmark is at github.com/anshumanbh/openclaw-advisory-benchmark.
I'm genuinely curious how different tools perform. If you run your scanner against this benchmark, I'd love to hear about it. Open an issue, submit a PR with your results, or just reach out.
The goal isn't to embarrass anyone's tool. It's to raise the bar for how we evaluate security scanners — with real code, real vulnerabilities, and honest results.
Built with help from Sage 🦉, who ran dozens of benchmark iterations overnight while I slept.
Until next time, ciao!