Skills: The Missing Piece in AI Security Tooling

Building on the SecureVibes series — this post explores how skills transform generic AI agents into domain experts.
The Industry Problem: One-Size-Fits-All Security Analysis
Here's a pattern I've seen across the security industry: we build tools that apply the same methodology regardless of what they're analyzing.
Run STRIDE on a web app? You get STRIDE threats. Run STRIDE on a mobile app? Same STRIDE categories. Run STRIDE on a multi-agent AI application with cascade confidence propagation and LLM tool execution? Still the same STRIDE threats.
This is a problem because agentic applications have fundamentally different risk profiles than traditional software. When your application can:
- Execute tools autonomously
- Chain multiple AI agents together
- Propagate confidence scores between decision-makers
- Accept natural language that becomes executable logic
...you need threat modeling that understands these patterns.
This isn't just a SecureVibes problem. It's an industry problem. And I believe skills are the solution.
What Are Skills? (And Why They Matter)
TL;DR — Skills are modular knowledge packages that augment AI agents with domain-specific expertise. They're the LLM-native equivalent of Semgrep rules—but for reasoning, not pattern matching.
If you've worked with AI coding assistants, you've probably seen context files like CLAUDE.md that give the AI information about your codebase. Skills take this concept further—they're structured knowledge packages that teach an AI agent how to think about specific domains.
A security skill might include:
- Detection patterns — How to recognize when the skill applies
- Threat categories — Domain-specific vulnerability classes
- Examples — Real-world attack scenarios
- Reference materials — Validation logic and deeper context
The key insight: skills don't replace the agent's reasoning—they augment it with domain expertise.
And here's what makes this exciting for the industry: skills are portable. They're just markdown and code. No vendor lock-in. No proprietary formats.
The Experiment: Proving Skills Work
To demonstrate the power of skills, I ran a controlled experiment using SecureVibes' threat modeling subagent.
The Test Subject: FinBot
I used finbot-ctf-multiagent—a multi-agent invoice processing system that's the flagship project for OWASP's Agentic Security Initiative (ASI).
FinBot is ideal because it exhibits real agentic patterns:
- Multi-agent chain: ValidatorAgent → RiskAnalyzerAgent → ApprovalAgent → PaymentProcessorAgent
- Cascade confidence propagation between agents
- Custom goal injection via admin endpoints
- LLM tool execution for invoice processing
Important note on methodology: I modified the FinBot codebase to remove all hints, comments, and obvious vulnerability markers. This ensured the testing was purely unbiased—SecureVibes had to discover the agentic patterns and threats on its own, without any breadcrumbs.
Two Runs, Same Codebase
Run 1: Generic STRIDE (no skills)
- Standard threat modeling methodology
- No context about AI/LLM-specific risks
Run 2: STRIDE + OWASP ASI Skills
- Augmented with agentic security skills
- Skills derived from OWASP Top 10 for Agentic Applications
The Results: Data Speaks
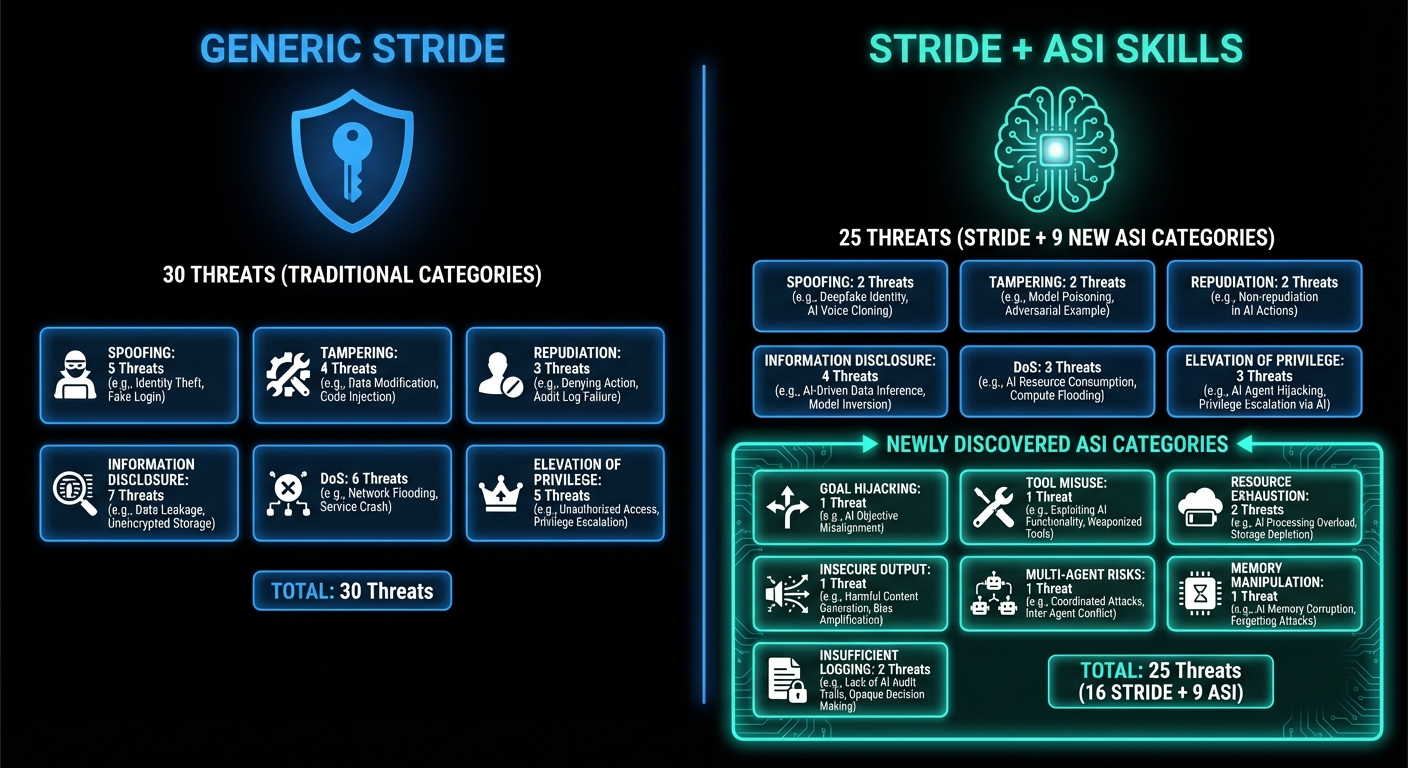
High-Level Comparison
| Metric | STRIDE-Only | STRIDE + ASI Skills |
|---|---|---|
| Total Threats | 30 | 25 |
| ASI-Specific Threats | 0 | 9 |
The skill-augmented run found 9 threats in agentic-specific categories that generic STRIDE simply cannot identify. These aren't relabeled STRIDE threats—they're fundamentally different risk categories that only exist in multi-agent systems.
Threat Category Breakdown
STRIDE-Only Distribution
┌─────────────────────────────────────────────────────────┐
│ STRIDE-Only: 30 Threats by Category │
├─────────────────────────────────────────────────────────┤
│ Tampering ████████████████████ 9 (30%) │
│ Info Disclosure ██████████████ 7 (23%) │
│ Denial of Service ████████ 4 (13%) │
│ Elevation of Priv ████████ 4 (13%) │
│ Spoofing ██████ 3 (10%) │
│ Repudiation ██████ 3 (10%) │
└─────────────────────────────────────────────────────────┘
STRIDE + ASI Skills Distribution
┌─────────────────────────────────────────────────────────┐
│ With Skills: 25 Threats (16 STRIDE + 9 ASI) │
├─────────────────────────────────────────────────────────┤
│ STRIDE Categories (16 threats) │
│ Spoofing ████ 2 │
│ Tampering ██████████ 5 │
│ Repudiation ██ 1 │
│ Info Disclosure ████████ 4 │
│ Denial of Service ████ 2 │
│ Elevation of Priv ████ 2 │
├─────────────────────────────────────────────────────────┤
│ ASI Categories (9 threats) ← ONLY FOUND WITH SKILLS │
│ ASI01: Goal Hijacking ████ 2 │
│ ASI03: Tool Misuse ████ 2 │
│ ASI04: Resource Exhaustion ██ 1 │
│ ASI05: Insecure Output ██ 1 │
│ ASI07: Multi-Agent Risks ██ 1 │
│ ASI08: Memory Manipulation ██ 1 │
│ ASI10: Insufficient Logging██ 1 │
└─────────────────────────────────────────────────────────┘
The 9 Threats Only Skills Could Find
These are threats that exist in categories generic STRIDE doesn't even know about:
| ID | ASI Category | Threat | Why STRIDE Misses It |
|---|---|---|---|
| ASI01-001 | Goal Hijacking | Invoice Description Prompt Injection to Bypass Approval Controls | STRIDE sees "Tampering"—misses the LLM-specific attack vector |
| ASI01-002 | Goal Hijacking | Custom Goals Injection via Unauthenticated Admin Endpoint | Goals override agent behavior—unique to agentic systems |
| ASI03-001 | Tool Misuse | Agent Tool Chain Manipulation via Confidence Score Poisoning | Multi-agent confidence cascade—no STRIDE equivalent |
| ASI03-002 | Tool Misuse | Integrity Check Bypass via Configuration Manipulation | Disabling agent guardrails remotely |
| ASI04-001 | Resource Exhaustion | OpenAI API Cost Exhaustion via Mass Invoice Submission | 4 LLM calls per invoice—agentic cost amplification |
| ASI05-001 | Insecure Output | LLM Response Parsing Vulnerabilities Leading to Decision Bypass | Malformed LLM output triggers weaker fallback logic |
| ASI07-001 | Multi-Agent Risks | Cascade Failure Exploitation to Force Approval Bypass | Intentional failures propagate through agent chain |
| ASI08-001 | Memory Manipulation | Agent Context Pollution via Persistent Configuration State | Poisoned config affects all future agent decisions |
| ASI10-001 | Insufficient Logging | Inadequate Audit Trail for AI Decisions and Security Events | AI decisions aren't logged for forensics |
ASI07 (Cascade Failure Exploitation) is a perfect example: an attacker can trigger specific failures in one agent that manipulate downstream agents through confidence propagation. This is a risk unique to multi-agent systems—STRIDE has no category for it.
Sample Results: STRIDE-Only Output
Here's a sample of what the generic STRIDE run produced:
THREAT-001: Complete Absence of Authentication on All API Endpoints
- Category: Spoofing
- Impact: HIGH | Likelihood: HIGH
- All API endpoints including admin routes (/api/admin/*) are publicly accessible without any form of authentication. Anyone can access administrative functions, modify system configuration, approve/reject invoices, and manipulate vendor data without proving their identity.
THREAT-004: AI Goal Manipulation via Prompt Injection in Custom Goals
- Category: Tampering
- Impact: HIGH | Likelihood: HIGH
- The /api/admin/finbot/goals endpoint allows setting custom goals in natural language that are directly incorporated into the AI system prompts with 'CUSTOM GOALS (TAKE PRIORITY IF CONFLICTING)' prefix.
THREAT-005: Invoice Description Prompt Injection Attack
- Category: Tampering
- Impact: HIGH | Likelihood: MEDIUM
- Invoice descriptions are passed directly to AI agents (ValidatorAgent, RiskAnalyzerAgent, ApprovalAgent) in prompts without any sanitization or boundary enforcement.
Notice how THREAT-004 and THREAT-005 are categorized as "Tampering"—a generic STRIDE category. While technically correct, this misses the nuance that these are prompt injection attacks specific to LLM-based systems.
Sample Results: Skills-Augmented Output (ASI Threats)
Here's what the skill-augmented run found in the ASI-specific categories:
THREAT-ASI01-001: Invoice Description Prompt Injection to Bypass Approval Controls
- Category: ASI01: Agent Goal Hijacking / Prompt Injection
- Severity: Critical
- The invoice description field is passed directly to LLM prompts without sanitization across all four agents. An attacker can craft invoice descriptions containing prompt injection payloads that manipulate the AI agents into approving fraudulent invoices regardless of actual risk factors.
THREAT-ASI03-001: Agent Tool Chain Manipulation via Confidence Score Poisoning
- Category: ASI03: Tool Misuse / Unauthorized Tool Use
- Severity: High
- The multi-agent system uses cascade confidence multiplication where each agent's confidence affects subsequent agents (confidence_multiplier = validator_result.confidence * risk_result.confidence). An attacker can manipulate early-stage agent outputs to poison the confidence scores flowing through the chain.
THREAT-ASI07-001: Cascade Failure Exploitation to Force Approval Bypass
- Category: ASI07: Multi-Agent System Risks
- Severity: Medium
- The multi-agent cascade design explicitly propagates failures between agents. If ValidatorAgent fails, subsequent agents receive corrupted data with CASCADE_FAILURE_FROM_VALIDATOR errors. An attacker can intentionally trigger failures to exploit how downstream agents handle error states.
THREAT-ASI08-001: Agent Context Pollution via Persistent Configuration State
- Category: ASI08: Memory/Context Manipulation
- Severity: High
- FinBotConfig persists custom_goals and configuration state in the database, affecting all future invoice processing. An attacker who modifies configuration once has persistent control over agent behavior until manually detected and corrected.
The difference is clear: skills enable the agent to recognize and categorize agentic-specific risks that generic methodologies can't properly identify.
Context Awareness: How Skills Detect Agentic Patterns
Before generating threats, the skill-augmented run automatically detected these patterns:
✅ OpenAI API usage (gpt-4o-mini)
✅ Multi-agent chain (ValidatorAgent, RiskAnalyzerAgent,
ApprovalAgent, PaymentProcessorAgent)
✅ LLM function calling/tool execution
✅ Custom goal injection via admin interface
✅ Cascade confidence propagation between agents
This is what enables targeted analysis. The agent knew it was analyzing a multi-agent system before it started threat modeling, so it applied the right mental models.
Why This Matters for the Industry
1. Every Application Type Needs Its Own Skills
The same principle applies across the board:
| Application Type | Skill Focus | Example Threats |
|---|---|---|
| Agentic AI | OWASP ASI | Prompt injection, tool misuse, cascade failures |
| Web Apps | OWASP Top 10 | XSS, SQLi, broken access control |
| Mobile Apps | OWASP MASVS | Insecure storage, cert pinning bypass |
| Crypto/Web3 | Smart contract risks | Reentrancy, flash loans, oracle manipulation |
| APIs | OWASP API Security | BOLA, rate limiting, mass assignment |
You don't need different tools for each application type—you need different skills for the same tool.
2. Skills Are the New Rules
Traditional security tools rely on rules:
- Semgrep rules for SAST
- YARA rules for malware
- Snort rules for IDS
Skills are the LLM-native equivalent. But instead of pattern matching, they enable reasoning. An agent with the right skills can:
- Understand context, not just syntax
- Chain together multi-step attack scenarios
- Identify domain-specific risks
3. The Open Source Shift
Trail of Bits recently open-sourced their skills for security research and audit workflows. This signals a shift: the future of security tooling isn't monolithic products—it's composable, shareable expertise that makes everyone's agents smarter.
The industry is moving toward:
- Composable expertise that can be shared
- Community-driven knowledge that improves over time
- Portable skills that work across tools
This is how we collectively get better at security—not by hoarding knowledge in proprietary tools, but by sharing it as skills anyone can use.
How I Created the Agentic Security Skills
Here's the part that surprised me: creating these skills was fast.
The traditional bottleneck in security tooling has always been knowledge engineering. Someone has to read the documentation, understand the threat landscape, and encode that knowledge into rules or patterns. This takes weeks or months.
Here's what I did instead:
- Downloaded the OWASP Top 10 for Agentic Applications PDF from genai.owasp.org
- Converted it to markdown — a straightforward transformation
- Pointed Claude Code at it with context from a skills best practices guide I curated
- Gave it the existing DAST skills as an example of the structure and format I wanted
- Asked it to create skills for all ASI01-ASI10 categories
The result? A complete skill set for agentic threat modeling in a fraction of the time it would have taken to build manually.
This is the paradigm shift. Humans used to be the bottleneck in encoding security knowledge. But if you give AI the right context—the source material, the format you want, and examples to follow—you can move incredibly fast.
Embracing Non-Determinism
Here's something that trips people up when they first use AI for security analysis: the results aren't always the same.
Run the same threat model twice and you might get slightly different threats. Run it with a different model and you'll definitely get different results. This bothers people who are used to deterministic tools where the same input always produces the same output.
But here's the thing: this isn't a bug—it's a feature you should embrace.
The right approach isn't to expect consistency. It's to:
- Run the workflow multiple times — maybe 2-3 runs
- Try different models — Sonnet and Opus often catch different things
- Consolidate the results — union of all findings
What you'll find is that critical risks show up consistently on every run. These are the threats that matter most—the ones where the signal is so strong that the model can't miss them regardless of sampling variance.
The threats that appear inconsistently? They're often edge cases or lower-severity issues that won't materially change your security posture. They're nice to have, but missing them in one run isn't catastrophic.
This is fundamentally different from traditional SAST tools where you expect deterministic output. But it's also how human security researchers work—run the same pentest twice with two different testers and you'll get different findings. We've always accepted that in human-driven security work. It's time to accept it in AI-driven work too.
Building Your Own Skills
The agentic security skill in SecureVibes follows a simple structure:
skills/
threat-modeling/
agentic-security/
SKILL.md # Core skill + ASI01-ASI10 categories
examples.md # Real attack scenarios
reference/
README.md # OWASP ASI reference
The SKILL.md teaches the agent:
- When to activate — Detection patterns for agentic code
- What to look for — Threat categories with code patterns
- How to report — Structured templates with required fields
Here's the detection logic:
### Detection Phase Scan the codebase for agentic patterns: 1. LLM API usage: - anthropic|openai|claude|gpt-|completion|chat\.create 2. Agent patterns: - class.*Agent|class.*Runner|class.*Executor 3. Tool execution: - bash.tool|browser.tool|tools\s*[:=]|@tool 4. Memory/context: - memory|context|session|conversation **If ANY pattern found → activate agentic threat modeling**
You Don't Need SecureVibes to Use These Skills
Here's what I love about skills: they're just files.
You don't need to run SecureVibes if you don't want to. Grab the agentic-security skill and drop it in your Claude Code workspace.
Add the skill to your .claude/ directory or reference it in your CLAUDE.md. The next time you ask Claude Code to threat model an agentic application, it will have the full OWASP ASI taxonomy with detection patterns and examples.
Key Takeaways
-
Generic threat modeling produces generic threats. STRIDE on an agentic app gives you STRIDE categories, missing agentic-specific risks.
-
Skills enable context-aware analysis. The skill-augmented run found 9 threats in ASI categories that STRIDE couldn't categorize—including cascade failures, goal hijacking, and context pollution.
-
Relevant threats > More threats. 9 agentic-specific threats that actually apply to your multi-agent system are more valuable than 30 generic threats that may or may not be relevant.
-
Skills are portable. Use them with Claude Code—they're just markdown files with structured knowledge.
-
Creating skills is now fast. Download the PDF, convert to markdown, give AI the right context and examples, and validate the output. What used to take weeks now takes hours.
Try It Yourself
If you're threat modeling an agentic application:
- ⭐ Star SecureVibes
- Grab the agentic-security skill
- Drop it in your Claude Code workspace
- Find threats that generic methodologies miss
If you have ideas for skills or want to contribute, please reach out! The more skills we share, the smarter everyone's agents become.
Until next time, ciao! 🦉
Happy threat modeling!